


























万博ANSYS的博客
2022年3月16日
模拟速度vs.精度:AI和gpu的平衡
在速度和准确性之间总是有一个权衡,但当涉及到模拟时,使用人工智能/机器学习(AI/ML)与图形处理单元(gpu)的结合正在打破平衡,提供两个世界的最佳:快速创新和更高的信心。通过使用AI/ML增强模拟方法,我们已经看到一些应用程序的速度提高了40倍,而这只是一个开始。
模拟用于分析各行业日益复杂的多物理场和系统级现象,包括推进电气化、自主、5G和个性化医疗的下一代产品面临的挑战。万博网它使我们的客户能够解决曾经无法解决的问题,并接受虚拟原型,这有助于节省时间和金钱,同时提高质量。然而,尽管模拟比物理测试和原型设计快很多倍,但市场需要更快的创新,Ansys在过去50多年来一直在不断地提供创新。万博
在英伟达GTC,在3月21日至24日举行的全球AI会议上,我将解释Ansys仿真解决方案如何利用AI/ML和NVIDIA gpu来提高客户的生产力,增强现有的加速万博模拟运行的方法,增强工程设计,并提供更大的商业智能见解。这是我演讲的预览。顺便说一下,我下面提到的所有机器学习算法都是在NVIDIA上运行的A100Tensor Core GPU,利用ML软件堆栈。
流体流动人工智能与仿真的结合
当你用Navier-Stokes方程求解大范围流动问题时,用有限元或有限体积方法求解大范围流动问题是很复杂的。你可以通过关注整体的小块来提高速度,然后学习这些小块是如何连接在一起来理解更大的区域。这就是ML的用武之地。我们可以创建一个算法,取一个单一的小的解决方案块,并在不同的区域移动它来解决更大的流模型。
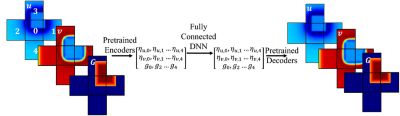
使用这个稳态流求解器作为基础,然后我们可以将其扩展为一个瞬态ML求解器,使用同样的方法关注小区域来加速解决方案,这使我们能够预测流如何随时间变化。所以,我们有了基于ml的稳态和瞬态流解的方法。现在,我们需要训练它。
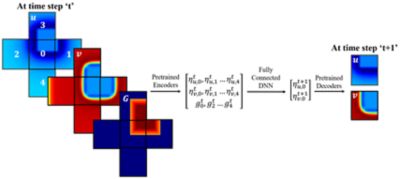
我们所做的是采用基于ml的流求解器,并将其与我们的万博Ansys流利这样它就是循环中的求解器。从本质上讲,这使得数据驱动的神经网络能够针对各种流体变量进行大规模训练。
将ML与Fluent集成在管道流体流动和汽车外部空气动力学方面的初步结果表明,使用单个CPU解决问题的时间要快30-40倍。GPU的能力可以提供额外的5-7倍的计算速度,并有潜力使用分布式GPU架构进行扩展。gpu为基于ml的方法提供了巨大的模拟加速潜力。
用AI-ML调整湍流模型
另一个结合ML和仿真的例子是湍流建模。紊流最精确的解算器是直接数值解(DNS),但这需要大量的时间,所以人们使用称为大涡模拟(LES)的近似方法,它比DNS更快,而且仍然相当准确。一个更快的近似是Reynolds-average Navier-Stokes (RANS)方程,这就是Fluent所使用的。RANS方程不如LES准确,因此我们使用广义k-omega (GEKO)模型来获得LES的精度水平,同时利用RANS的速度优势。然而,识别GEKO参数需要模拟专家的专业知识。这就是我们应用ML的地方。
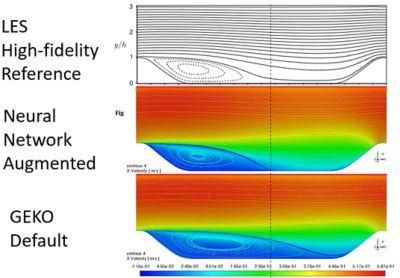
使用基于ml的方法,我们自动调整GEKO参数,而不是手动调整以获得LES模型的准确性。
找到放置精细网格的最佳位置
另一个使用ML来寻找关键位置以加速模拟的例子可以在电子领域找到。在模拟由印刷电路板(pcb)上的集成电路(ic)或作为3ic堆叠而成的电子芯片封装时,在最精确的水平上模拟它们的热性能可能需要很长时间。通常,人们通过使用自适应网格技术来加快这一过程。节省了大量的时间。在一个10x10芯片上热法模拟,采用自适应细网格划分可将运行时间从4.5小时减少到33分钟。
你可以想一个网作为用来模拟特定现象的信息网格。一个更细的网格包含更多的信息,需要更长的时间来解决,但更准确。理想情况下,您应该只在芯片“热点”上最需要的地方使用较细的网格,而在其他地方使用较粗的网格,以获得快速和准确的结果。使用ML,我们能够自动检测芯片热点,并通过预测温度衰减曲线在需要的地方应用精细网格。
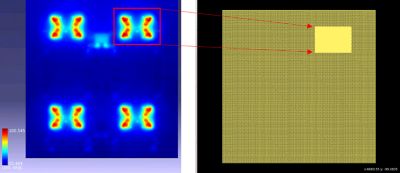
如果您集成了这两个概念——自适应网格划分和自动热点检测——您可以节省大量时间。例如,在一个16mmx16mm的大芯片上,即使是一个200x200微米的粗网格也需要17分钟的运行时间。使用基于ml的自适应网格放置精细的,10x10微米的网格,在他们需要的地方,它运行在2m 40s。它提供了准确性和速度。
在NVID万博IA GTC加入Ansys
我不想透露太多,因为我想让你和我一起参加NVIDIA GTC。我的演讲,人工智能在工程仿真中的应manbet用,将于3月23日星期三下午2点举行。太平洋。您可以免费注册以了解更多关于上述示例的信息,此外,我将分享我们如何使用ML来提高数字孪生的准确性,并加快复合材料结构的复杂并发多尺度结构模拟。
一定要看看我的Ansys同事们的演讲:万博
Scopri cosa può fare 万博Ansys per te
Scopri cosa può fare 万博Ansys per te
联系我们
Contattaci急速地
