

























万博ANSYS的博客
2022年5月11日
万博Ansys Fluent / GPU / (1)
職場からの帰宅,ニューヨークからロンドンへのフライト,会社がアップグレードしようとしないオフィスの古いコーヒーメーカー・・・。数値流体力学(CFD计算流体动力学):シミュレーションと同様に,これらはすべてスピードアップから恩恵を受けます。
長年にわたり,CFDシミュレーションの加速で重要な役割を果たすものの1つとしてハイパフォーマンスコンピューティング(HPC:高性能计算)があり,さらに近年になって,これはグラフィックスプロセッシングユニット(GPU:图形处理单元)に拡大されました。
gpu, gpu,。GPUは,かなり長い間CFDアクセラレーターとして使用されており,万博Ansys流利★★★★★★★★★★★ただし,実際に得られる局所的な加速は問題によって異なります。。そのため,ここでは,CFDシミュレーションが複数のGPU上でネイティブに実行されたときのGPUの潜在力をお見せしたいと思います。
これは,当社のブログシリーズ“万博Ansys流利のためにGPUのフルパワーを解き放つ”の第1弾です。このシリーズでは,シミュレーション時間,ハードウェアコスト,電力消費の削減にGPUがいかに役立つかについて説明します。(1)、(1)、(2)、(2)、(3)、(3)。。
32
中文:中文:。。このサイズのシミュレーションを実行するには,数千~数万コアと,数日(場合によっては数週間)の計算時間が必要となります。シミュレーション時間を数週間から数日,または数日から数時間に短縮し,同時に電力消費も大幅に削減できる方法があるとしたらどうでしょうか。………………。
整整整整,整整齐齐,整整齐齐,整整齐齐,整整齐齐,整整齐齐,整整齐齐。。
- 你说得对
- 排出量削減
- 这是我的最爱
- ハイブリッドおよび電気のパワートレインオプションの開発
しかし,持続可能性の取り組みは,最終製品(この場合は自動車)の運用に限定するのではなく,製品の設計プロセスにも拡大する必要があります。これにはシミュレーションが含まれますが,万博Ansysではシミュレーション中に消費される電力量を削減したいと考えています。

自動車の外部空力シミュレーションは完全にGPU上で実行することによってスピードアップ可能
ここに示すシミュレーションでは,流利を使用して,CPUとGPUのさまざまな構成でベンチマークのDrivAerモデルを実行し,パフォーマンスを比較しました。その結果,単一のNVIDIA GPU A100が,80コアの英特尔®Xeon 8380®铂を含むクラスターより5倍高いパフォーマンスを達成したことがわかりました。NVIDIA GPU A100を8個にスケールアップすれば,シミュレーションは30倍以上スピードアップできます。
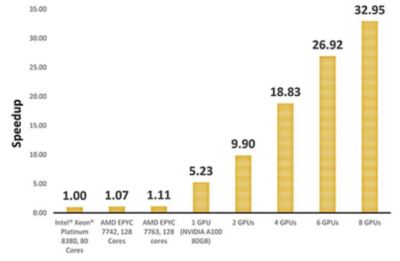
GPU活用時の自動車外部空力シミュレーションのスピードアップ
より短時間で結果が得られれば,お客様の効率は向上しますが,それでは終わりません。このようなシミュレーションの実行に必要な電力を大幅に削減することにより,お客様の電気料金を削減する(同時に地球を助ける)こともできます。
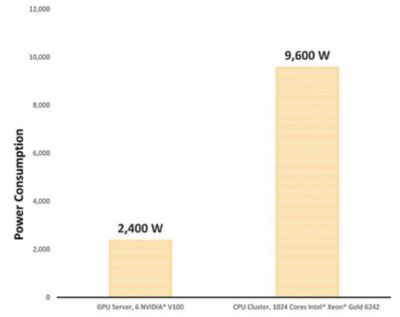
1024年コアの英特尔®Xeon®6242黄金を含むCPUクラスターの電力消費量を見ると,それは9600 wでした。英伟达®V100 GPUが6個のサーバーと比較すると,その電力消費量は4分のの2400 wまで削減されました。
これらのベンチマーク結果は,NVIDIA®V100 GPUが6個のサーバーを選ぶ企業が,同等のHPCクラスターと比較して電力消費を4分の1に削減できることを示しています。。
gpu
ネイティブのGPUソルバーでシミュレーションを実行することは,会社の持続可能性の取り組みにおいても,結果の待ち時間の短縮においても,直ちに大きな影響が出る可能性があります。,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,過去40年以上にわたって,流利は広範囲のアプリケーションで広く検証されており,業界をリードする精度で知られています。流利的内で利用可能なCPUとマルチGPUソルバーはいずれも同じ離散化方法と数値解析法を基に構築されており,実質的に同一の結果をユーザーに提供します。
以下の2つの標準的なケースは,層流と乱流レジームから原理をシミュレーションする,確立されたCFD検証です。。
这是一个非常复杂的过程
球を越える流れの実験研究や数値研究に関する文献は豊富にあり,外部空力検証の基本的なベンチマークの役割を果たしています。この最初のテストでは,レイノルズ数が100に等しく,流体が球を避けて進み,円筒の背後に時不変の渦構造を形成する層流条件を選択しました。。
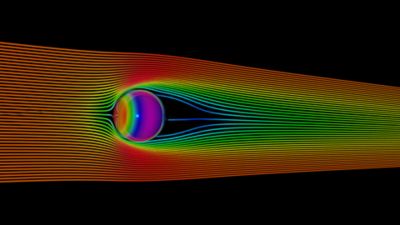
球を越える層流の速度流線と圧力分布のベンチマーク
表1に示すように,ネイティブのGPU実装は,誤差率わずか-0.252%で抗力係数を非常に正確に計算します。

表1.(Cd)
後方に面したステップ
。。沃格尔·伊顿2★★★★★★★★★★★★★★★★★★★★★★★★さまざまな平面におけるチャネルの長さ方向の速度プロファイルを,公表された実験データと比較することにより,CFDコードがテストに加えられます。

後方に面したステップの速度ベクトル
CPU,通达,通达,通达,通达3、4★★★★★★★★この同じ問題をネイティブのマルチGPUソルバーで解析すると,以下に示すように,実質的に同一の結果が得られます。これは,流利で利用可能なCPUとGPUがいずれも同じ離散化方法と数値解析法を基に構築されているからです。
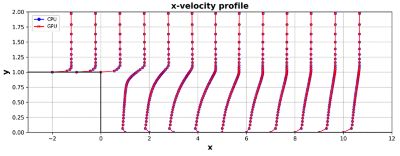
cpu gpu
すべてのメッシュタイプを受け入れる非構造化有限体積ナビエ・ストークスソルバーの,このネイティブのマルチGPU実装は,実に斬新であり,精度を落とすことなくCFDの新しい基準を設定します。問題に対してGPUの潜在力を利用することによって得られる大幅なスピードアップをご覧いただきたい場合は,今すぐ中文:啊啊啊啊啊啊啊啊啊啊。
参考文献
- Turton r;和Levenspiel, O.,关于球体阻力相关性的简短说明,粉末技术。, 47, 83-86, 1986
- Vogel j.c.和Eaton, j.k.(1985)后向台阶下游的综合传热和流体动力学测量。[j] .中国科学:自然科学,2009(1):1 -9。
- Smirnov, Evgueni & Smirnovsky, Alexander & Shchur, Nikolai & Zaitsev, Dmitri & Smirnov, P.(2018)。后向台阶湍流和传热的RANS和IDDES解的比较。热和传质。10.1007 / s00231 - 017 - 2207 - 0
- 刘建军,刘建军,刘建军,刘建军。(2020)。基于CFD的修正后台阶流体流动数值模拟。国际工程与技术研究杂志。第七卷,第九期
万博Ansys
万博Ansys
联系我们
英文怎么说
